Wan 2.1 本地部署教程
开源AI视频模型:Wan2.1。这是由阿里巴巴通义万相团队开发的下一代视频生成模型,它在AI驱动的视觉内容创作领域实现了显著的飞跃。

WAN2.1 是一套全面开放的视频生成模型,它突破了视频生成的界限。1.3B型号仅需要8.19 GB VRAM,使其与几乎所有消费级GPU兼容。它可以在大约4分钟内在RTX 4090上生成5秒的480p视频(无需量化等优化技术)。它的性能甚至可以与某些封闭式模型相媲美。
在 SOTA性能方面,始终优于多个基准测试的现有开源模型,并且可以和最先进的闭源商业模型相媲美!
通过博客介绍的方法已经生成和例子一样的视频,并且修改随机种子生成同主题的不同视频。


文字转视频
1、安装Git。使用ComfyUI软件需要用到Git。下载地址:https://git-scm.com/
2、安装ComfyUI。下载地址:https://www.comfy.org/
3、下载文本编码器 :umt5_xxl_fp8_e4m3fn_scaled.safetensors,下载后放入路径:ComfyUI/models/text_encoders/
4、下载VAE:wan_2.1_vae.safetensors,下载后放入路径:ComfyUI/models/vae/
5、下载视频生成模型:wan2.1_t2v_1.3B_fp16.safetensors,下载后放入路径:ComfyUI/models/diffusion_models/
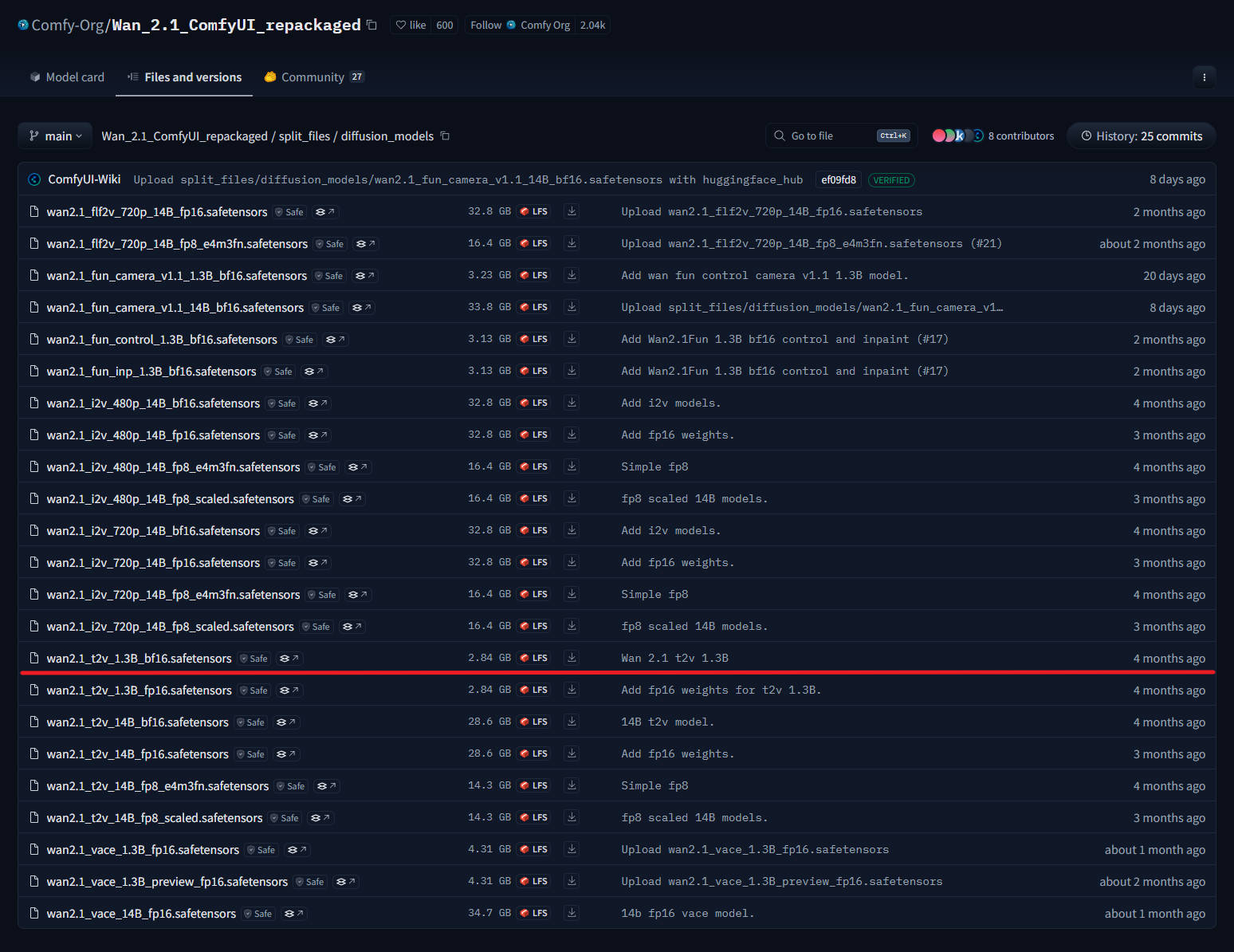
注意:建议使用 fp16 版本而不是 bf16 版本,因为它们会产生更好的结果。
质量等级(从高到低):fp16 > bf16 > fp8_scaled > fp8_e4m3fn
这些示例使用 16 位文件,但如果内存不足,则可以使用 fp8 文件。
6、文字转视频工作流:下载 Json 格式的工作流,右击保存成Json格式文件。
到这一步就可以文字生成视频了。保存工作流文件后,直接拖拽进入ComfyUI软件。
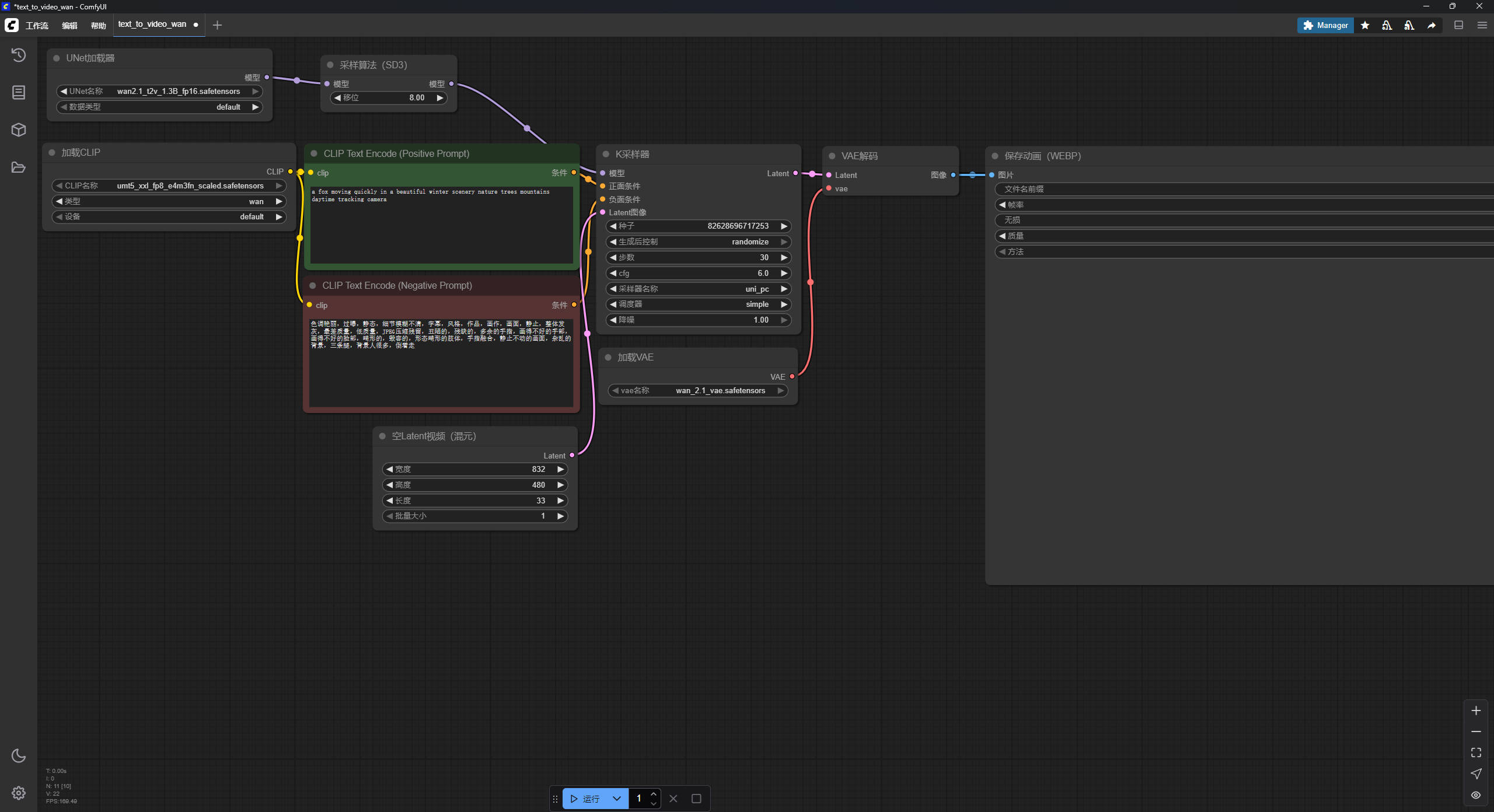
已经做好设置了,直接点击下面的运行,就可以生成和原文一样的视频。
绿色的方框填正向关键词,红色的方框填写反向关键词。
图片转视频
1、下载 :wan2.1_i2v_480p_14B_fp8_e4m3fn.safetensors,下载后放入路径:ComfyUI/models/diffusion_models/
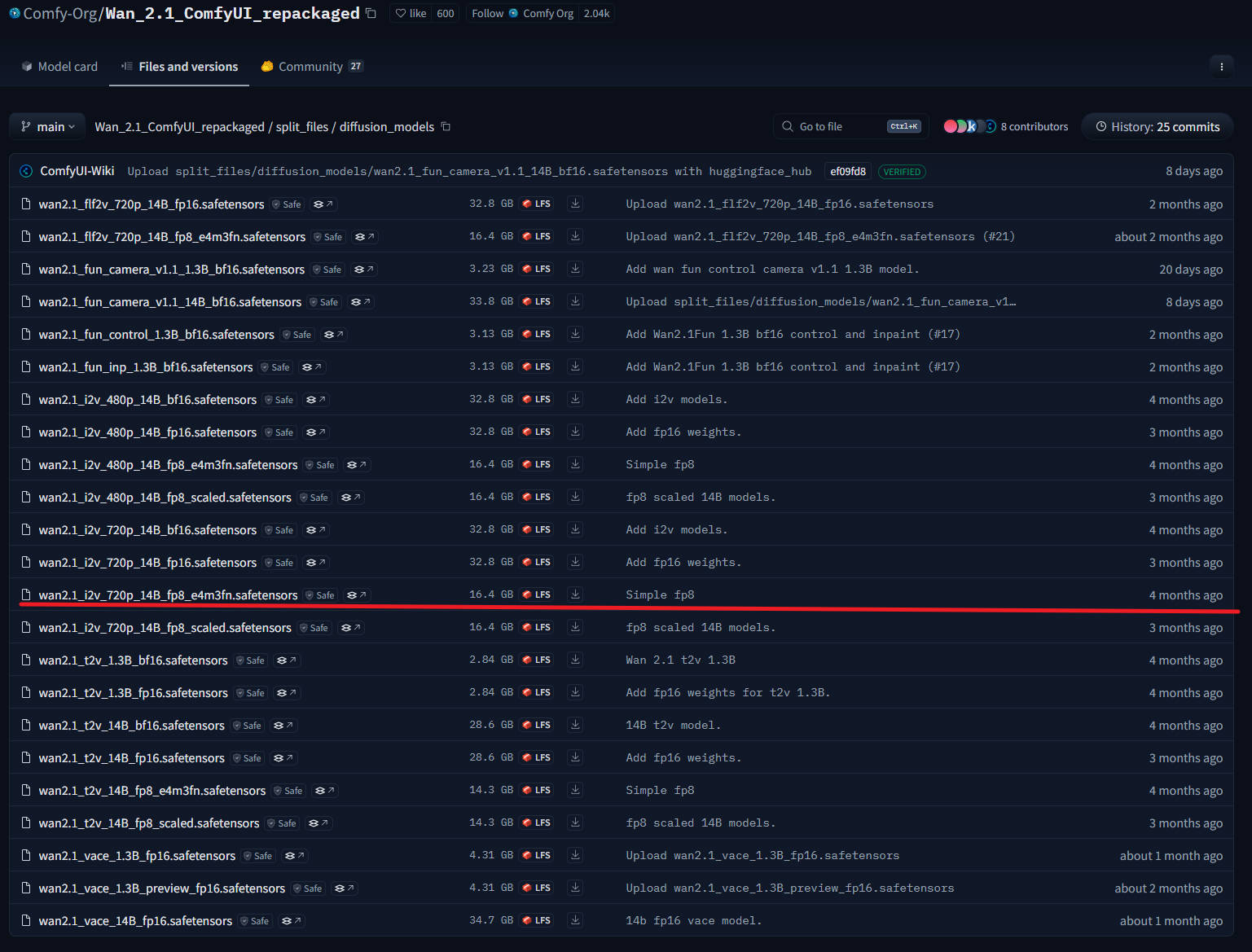
2、下载:clip_vision_h.safetensors,下载后放入路径:ComfyUI/models/clip_vision/
此示例仅生成 512×512 的 33 帧,因为我希望它易于访问,但模型可以做的不止这些。如果您有硬件/耐心运行它,720p 模型就相当不错。
3、图片转视频工作流:下载 Json 格式的工作流,右击保存成Json格式文件。
将工作流文件拖拽到ComfyUI软件,打开后如图:
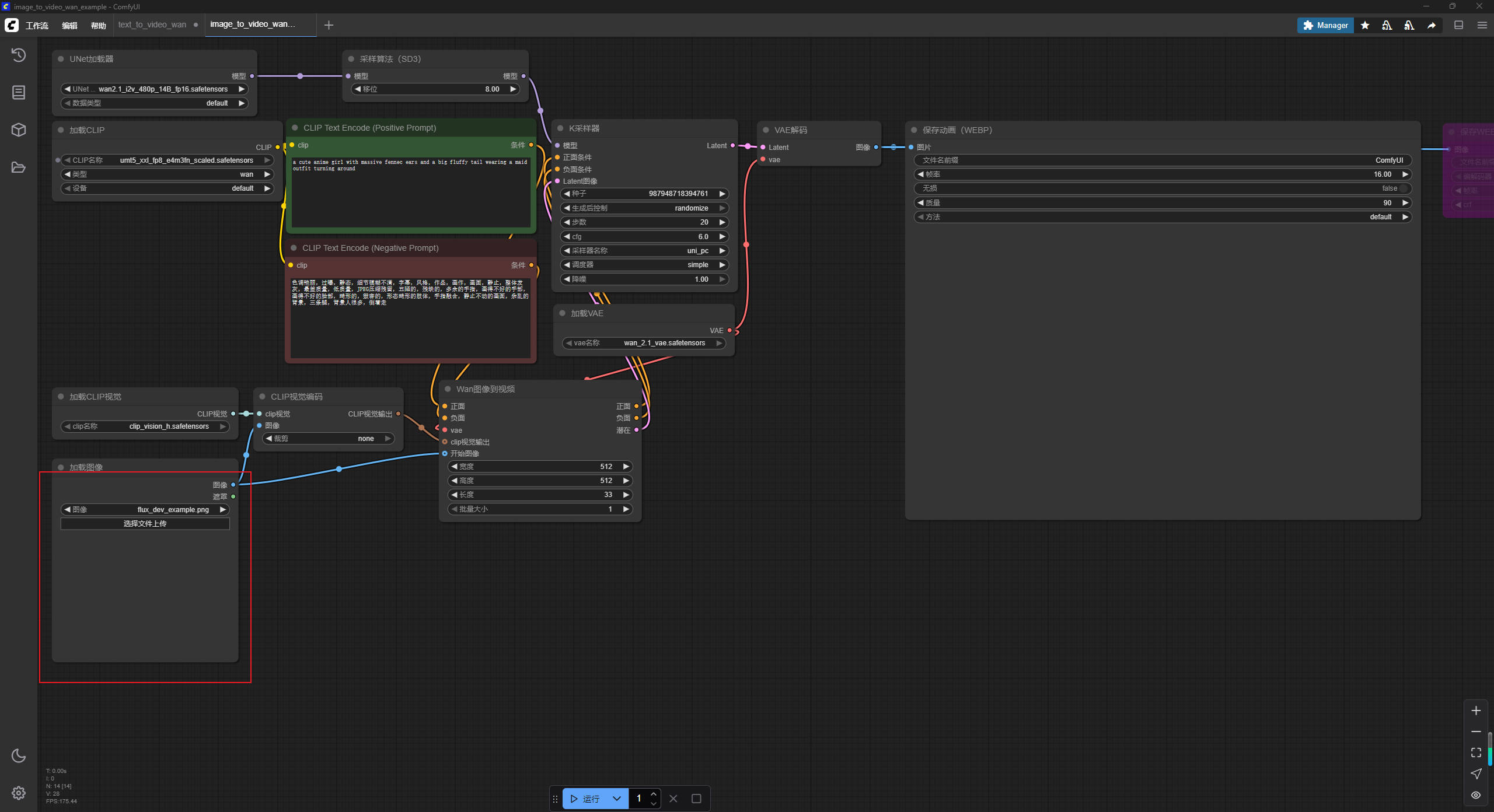
左下角选择原图片文件。
绿色的方框填正向关键词,红色的方框填写反向关键词。
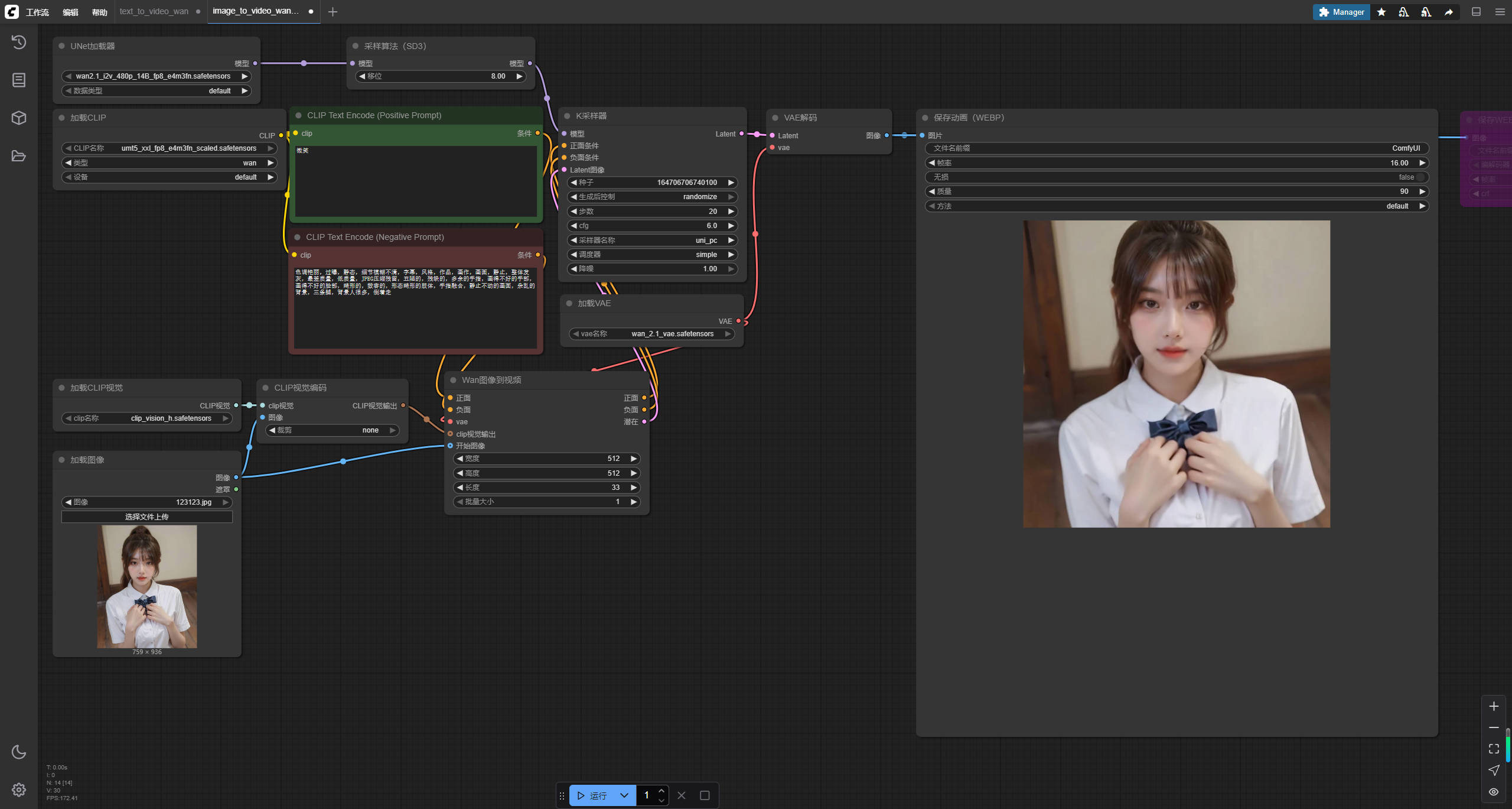
然后点击最下面运行。等待一会儿就OK了。
下面是我生成的效果。图片素材是AI绘制。

声明
本站部分图片、资源、书籍、软件等内容来源于网络,本站所供资料仅供学习之用,任何人不得将之他用或者进行传播,否则应当自行向实际权利人承担法律责任。因本站部分资料来源于其他媒介,如存在没有标注来源或来源标注错误导致侵犯阁下权利之处,敬请告知,我将立即予以处理。请支持正版。
原文转自——零度博客

 晋公网安备14030302000174号 |
晋公网安备14030302000174号 |